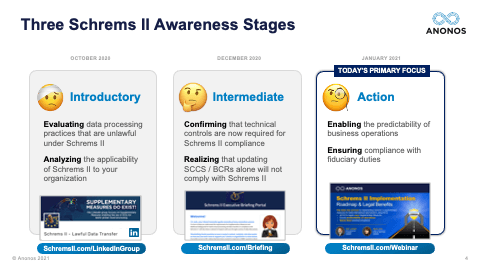
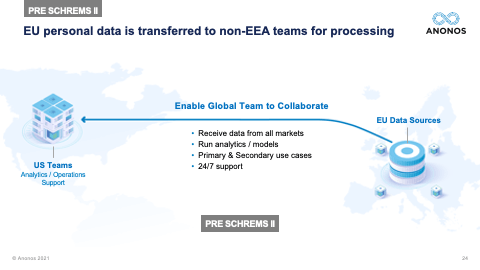
[55:33] So with that, we will be sending you all the Guidebook, but we have a couple of survey questions to ask and then we'll go into the questions that have been submitted by the audience. So, if you look at your screen, we'd love to know if you want and need access to the portal. We can also send you a special invite, so you can share it with your colleagues and facilitate group awareness and knowledge very quickly. And then, if you scroll down to the second question here - and I want to repeat and emphasise the portal has videos, very telling videos from the EDPS and NOYB. And then if you scroll down, the question two is: “Are you interested in a 30-minute personal briefing? Or maybe a 60-minute personal briefing where we can go into detail on the types of things that are covered in the Guidebook and help you understand the legal principles that undergird what we're talking about?” Again, this is a Board-level issue. What have you looked at? We would welcome the opportunity to expose you to the benefits of GDPR-compliant Pseudonymisation. You will get the Guidebook because you've already registered for the event. And whether you want to call us after you've read the Guidebook or before, if you're interested please vote and let us know because that enables us to figure out the best ways to meet the needs of our audience. Also, the Guidebook has a checklist. It has a checklist that you should use in evaluating any vendor that is talking about providing Pseudonymisation.
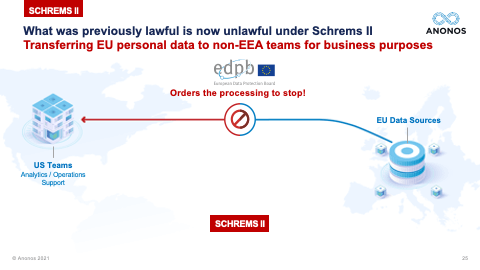
[57:15] Let's take a step back. Pseudonymisation embodies, reflects, and enforces functional separation. You need to ensure that the approach that's taken allows the separation of identity from information value enabling information value to be processed lawfully and then rejoined or re-linked under controlled conditions, so that in fact, the business people get what they want and yet the lawyers get what they need. And what they need is a defensible position as to why the actions they've taken show a good faith compliance effort to their obligations. Maggie pointed out Schrems II is a ruling by the Supreme Court of the Land - the Court of Justice of the European Union - six months ago, unappealable, no grace period. We help you to have a defensible position.
[58:15] So, with that, we will move on to some of the questions that we got from the audience. So, let's look at the first one. And this one is for you, Maggie. Someone asked you to provide more detail on Pseudonymisation versus anonymisation, and they've heard about your famous toothbrush analogy, if you could please share that. So, again, the question is: “Can you please go back and describe the benefits of Pseudonymisation over anonymisation with a quick rendition of your toothbrush analogy?”

Magali Feys
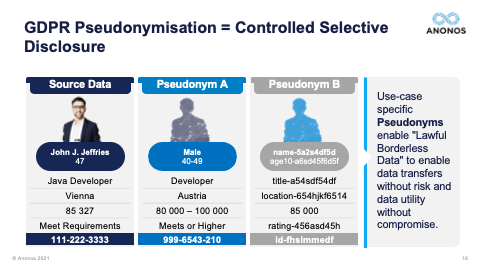
[58:48] Yeah. So, what happened actually in the past is if you put the analogy, we were brushing our teeth and we let the water run. Well, the problem was that we had no controls on how much water, where the water was going, and what to do with it. Now, if we would apply on that analogy anonymisation, that means that therefore you must be not able to anymore re-link the information value with the identity, and you really have to throw it away meaning that you would open up the tap. So, first of all, you would close the tap while brushing your teeth, and then open it up. But anonymisation on a lot of data sets would mean that you only get three drops of water. Now the problem is, as you all already stated in some of the questions in certain use cases, what if you use a bad toothpaste and you need at least a glass of water to get the taste out of your mouth? Or you're there with four people and you need four glasses of water? Anonymisation will really restrict you in the data utility and in the utility to use your data. What is the benefits of Pseudonymisation is that same as anonymisation, you turn off the water whilst brushing your teeth. But when you need the water, you have the controls in place to actually say: “Well, let's open the tap and anonymisation would only give you the tree drops.” But with Pseudonymisation, you could say: “Well, in this use case specific, I really need one glass of water.” And it's controlled but this is contained in that glass and you use it because you used the bad toothpaste. In some cases, it's a good toothpaste and the three drops would get you where you need. But sometimes you even need the four glasses. So, that is really the benefit of use case specific Pseudonymisation is that you still can have the data utility, but you do it in a controlled way. And if you think of it, that is exactly the spirit of Article 25 within the GDPR.

Gary LaFever
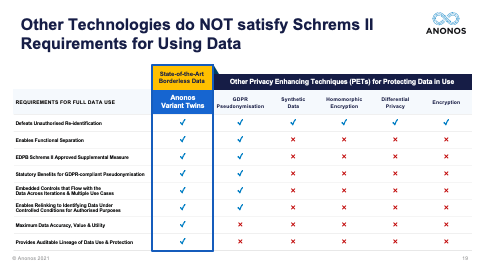
[01:00:57] Thank you very much, Maggie. It's nice that your toothbrush analogy has become famous. But I do think it's a great way of identifying the difference in value. The second question here and I'm going to have to go back in slides. I had a request to go back to slide 19. So, just a minute, I'm not sure what that one is. Let me bring it up. Okay. Happy to do so. So, someone asked if I could go back to slide 19 and spend a little more time on this. So, I will. Give me one second, please. Okay. All right. So, this is slide 19. And I know I went over this very quickly. That's not slide 19. One moment, please. User error. Okay. Slide 19. So, the thing I would like to really point out here is we're not denigrating the capabilities of synthetic data, homomorphic encryption, differential privacy, or encryption. They were all designed to do certain things, and they do them well. It's when you get both the business people and the lawyers to the table at the same time that you realise that oftentimes they were created at a simpler time.
[01:02:26] Differential privacy, let's just take that as an example. Differential privacy is premised on the existence of a privacy budget. And people can ask questions, but as they start to use up that privacy budget, as they start to get closer and closer to identifying data, they're either not allowed to ask those questions or there is noise or perturbation or other things done to the data so that the results are less accurate. Differential privacy works very well for certain use cases. But it has to be remaining within a perimeter, you must know all the data uses, you must know the data users, you must have control over the data because those three elements must be known and fixed in order for the privacy budget to apply. You will see differential privacy vendors talk about how they watermark the data, and they say it's great because when they watermark the data, you'll know who took it outside of the perimeter. Well, that's fine, except it's like the proverbial cattle out of the barn or the horses out of the barn. It's too late. And so, differential privacy and most anonymisation techniques are built to be constrained within a perimeter and they work within that perimeter. But when you go to share and combine data and when you go to transfer it internationally, it's no longer within a perimeter.
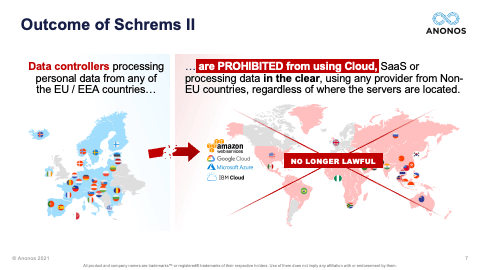
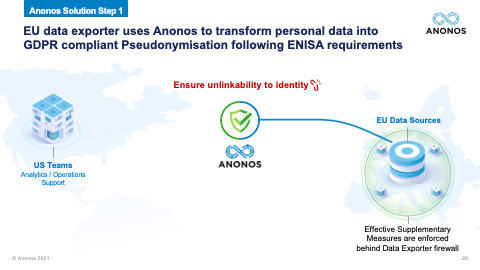
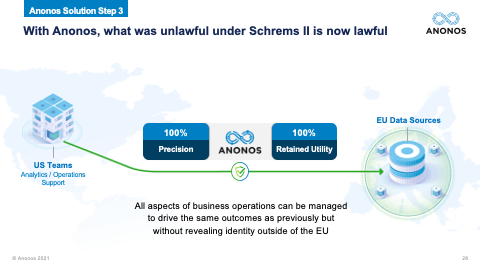
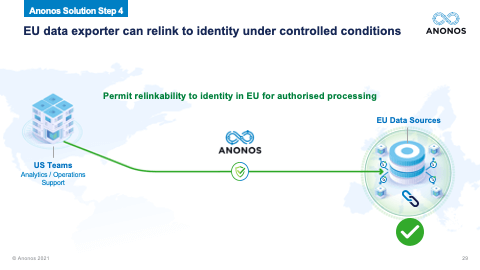
[01:03:49] And one of the real significant holdings of Schrems II was the fact that contracts, treaties, and I like to say words alone are simply not enough anymore. And the reason they're not enough is because foreign governments aren't parties to those contracts. And so, a foreign government, let's say the US government goes to a public cloud provider. And it says: “Under FISA, I demand that you give me the data that you have access to. And I know that when the data is being processed by you, it's in the clear. I want that data.” The government is not in violation of a contract. They're not party to a contract. And the public cloud provider will be in violation of its obligations under that national statute if they don't provide the data. That's why Schrems II says any jurisdiction, which does not have an equivalent protection, you must have technologically enforced controls that ensure that when and if that foreign government says: “Give me that data,” that cloud provider can comply with their obligation to give them the data. But the data, when provided, doesn't reveal identity. And this is the power of functional separation, if I can separate the information value from identity, allow the information value to be processed, in the event that that information value was surveilled, there's no violation of the rights of the individuals because the data necessary to re-link and re-identify is back in the EU. And if you followed the ENISA suggestions for Pseudonymisation, it will not be subject to re-identification by the foreign government.
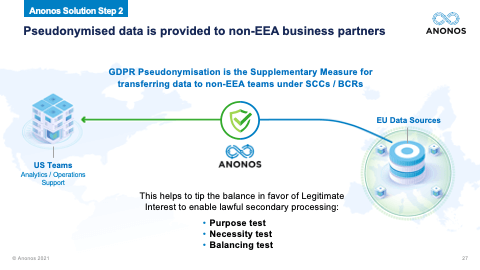
[01:05:37] So, I really want to highlight, you have to ensure that pseudonymised data is GDPR-pseudonymised data. So, again, the fact that these different technologies may in fact defeat unauthorised re-identification is not the end of the analysis because you need to satisfy your business teams requirements. And so, as you go through these, and I very much do encourage you when you get the Legal Guidebook to take a look at some of the statutory benefits of GDPR-compliant Pseudonymisation. Maggie touched upon some of those. And Maggie, now that we've allocated ourselves a little more time, could you touch upon the statutory benefits that exist under the GDPR? The one you just touched upon before I so rudely rushed you was the one about secondary processing and further processing. Could you touch a little bit more upon that?
Magali Feys
[01:06:30] Well, yeah, because as we’ve seen, in order, for example, we have seen that in hospitals and also with research institutions and I saw one of the questions also. One of the things if you want to publish a scientific article and you use data, you also must then save your data in a data repository in order to re-link the data and in order too for other scientists to verify whether your conclusions are indeed accurate and just. And so, we see that really by secondary use of data that it comes to legitimate interest. And then with medical data, you have, of course, also another grounds under Article 9. But by really using the technology, by implementing those technical safeguards, by using Pseudonymisation and having those controls that, for example, can then easily be exercised by a data access committee, we actually saw within the research that we were able to actually have more potential and more opportunities to use the data for the secondary use. So, although, there were and there are other aspects, I'm not saying, and I think neither is Gary that only applying Pseudonymisation is the Holy Grail and solves all of the problems. Indeed, there is still transparency to be looked at and other stuff. There are the other cornerstones of the GDPR, and we're not saying just toss them away. And if you have Pseudonymisation, then everything is done. But you will see that really implementing that and by really thinking about it from a Data Protection by Design factor that it really opens the fact to the opportunities to use the data and I'm really for innovation and I honestly think that we shouldn't make a binary choice between innovation and privacy, that actually both can be hand in hand together. It's not an equal balance all the time. I'm not saying that. But I think by applying and by really using the cornerstones, the ethical principles, the legal principles, and the technical safeguards as communicating vessels, that is the way forward. And actually, we see that coming back in the EDPB's Guidelines where they say that is exactly the sort of risk analysis you have to make. And a good example, if you don't believe me on that, but a good example is data minimisation. If you ask people of data minimisation, they will say: “Oh, it is only about the quantity of data.” Well, no, the GDPR specifically states that you can actually have a lot of quantity of data. But another way to achieve data minimisation is by actually implementing access rights. So, you see, a technical safeguards being used to actually comply with that legal requirement and you still have all your data, and that is exactly what Pseudonymisation is also doing for you.
Gary LaFever
[01:09:47] I really want to underscore something that Maggie just said. Pseudonymisation is not a silver bullet. Pseudonymisation is not a golden shield. Pseudonymisation is not a magic wand. But what it is, is a technical and operational measure that is specifically enumerated and rewarded under the GDPR if it's complying with the types of requirements and suggestions made by experts such as ENISA. And the Legal Guidebook that everyone who registered will get and a lot of the questions are: “Can we get copies of the slides?” Everyone who registered will get a link to a video replay, a summary, as well as the Legal Guidebook. And again, even if you didn't respond to the question, I would welcome the opportunity to have a one-on-one briefing. Maggie and I learn as much from these briefings as you do. So, do not think that you're imposing on us. We learn from hearing different perspectives from clients and prospects and that enables us to do a better job of what we do. So, I encourage you, if you're interested, reach out to me at gary.lafever@anonos.com because we would welcome the opportunity to talk to you about these things.
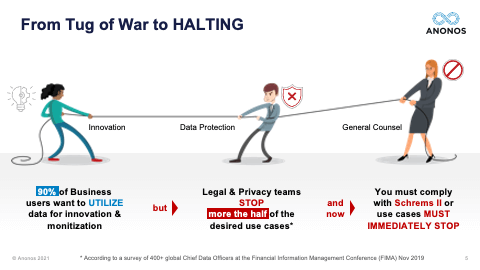
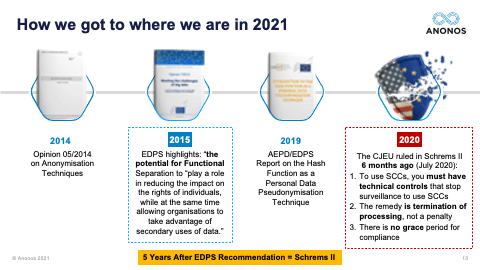
[01:10:59] So, the next one is a question I get asked quite often: “Do you think there will be a Schrems III?” And so, I'll answer this first, and then I look forward to Maggie's. I do not think they will be a Schrems III. And here's why, in my view, there won't be. It goes unnoticed by a lot of people. But just several months after Schrems II, the Court of Justice of the European Union came out with a number of rulings that impacted the UK and this was before Brexit, Brussels, or Belgium and France and they basically said: “You cannot be collecting data in mass forms under telco for potential use in the future.” So, the CJEU has made it very clear that the ruling of Schrems is not just restricted to the US. It applies to any country that does not have an equivalency ruling. And even within the EU, the principles could apply. So, I do not believe there will be a Schrems III because I believe any attempt to solve this tension and this tug of war that was on the one slide - and by the way, I wanted to point to this slide because this is the third most important slide. I told you I would tell you. The first most important slide from my perspective is the one that actually was the tug of war with the General Counsel saying no more. The second most important slide was the timeline that showed that from 2014 when there was Opinion 05/2014 on anonymisation up through Schrems, there was a huge shift and that Pseudonymisation is now a very powerful tool and not something to be derided as it was in 2014. And also that anonymisation, as made clear by the joint Spanish DPA and EDPS ruling is something that has such a high standard that not even the data controller can speak to it.
[01:12:49] So, from all of this, if I was to summarise why I don't think there's going to be a Schrems III is because what Schrems II says. Again, this is my view. You must have a defensible technologically enforced position. You cannot rely on words alone, whether those words exist in terms of use, in a contract, or a treaty, the rights of our data subjects - and this is fundamental rights and these are constitutional rights - cannot be abrogated away or negotiated away in contracts to which they're not parties. So, I do not believe that there will be a Schrems III. I do not believe that there will be a Privacy Shield 2. I do believe and hope that the US and EU government can come up with a trade deal, perhaps similar to what they've done with the UK that will acknowledge the need and importance for information. But don't forget, the UK-EU trade deal does not have an equivalency ruling. So, Maggie, if you would please share your perspective on whether or not you think there will be a Schrems III.
Magali Feys
[01:13:59] Well, I always say that depends on Max Schrems’ appetite for judicial procedures and knowing that there is WhatsApp I think he could go another round. Now, all kidding aside, I agree that we won’t probably see a Schrems III given the fact that if there would be a new proposition hopefully under the Biden administration for the EU-US transfers and an adequacy finding that with everything in mind the EU and the Commission will look at it with that perspective. And I agree that it probably will then not be as easy as having a Privacy Shield 2.0. So, I am inclined to agree with you, Gary, that probably there's not a Schrems III on the horizon.
Gary LaFever
[01:14:56] So, in the time that we have left, I’m going to hit some of these questions that we’ve had asked. First off, when we say that Pseudonymisation is not a magic wand, a silver bullet, and a golden shield, I want to call back in Anna Buchta’s comments. And again, this video is on the portal. Anna Buchta made it very clear that when the EDPB Guidance came out, it would still be possible to achieve the goals but they may have to be done differently. And what I mean by that is we are oftentimes asked: “Can Pseudonymisation fix Office 365? How do you do certain things?”
[01:15:37] The reality is change in business practices will be required. You will have to identify which practices have to occur within the EU and in which business practices can actually be transferred outside of the EU. And so, could Pseudonymisation “fix” Office 365? That would have to be a conversation with Microsoft. But the reality is what we're talking about - the kinds of processing we're talking about are where you're looking to capture the expertise from third parties. And that's why the two use cases that are identified as being unlawful - processing data in the public cloud in the clear and also transfer of data - are the two that we focused on because that actually is repurposing of data and further processing.
[01:16:24] And as Maggie mentioned, the capabilities and technical and organisational measures can actually help you to support winning as it were showing that the balancing of interest test actually does come out so that the rights of the data subjects are adequately protected, so that the data controller can move forward. And so, we do not purport that Pseudonymisation fixes everything, and I'm sure each of you have either internal advisors or external advisors that you work with. The reality is, you have to figure out what minimal changes will be necessary to your business practices and what can be outsourced as it were or transferred outside of the EU, or EEA, or equivalency countries. But changes will have to be made. And I believe this is where Romain Robert would say: “But those changes should have already occurred regardless of international data transfer when you look at your obligations under Article 25 - Data Protection by Design and by Default.” And this goes to another point that Maggie made. Data Protection by Design and by Default specifically cites data minimisation and specifically cites Pseudonymisation. And when they use data minimisation, they're not talking about restricting and limiting the amount of data that you have. They're talking about providing just the minimal level of identifying data necessary to accomplish a desired business result. That use case specific, context specific application of technology, that's Data Protection by Design and by Default. That's data minimisation, not in volume, but in use case and Pseudonymisation is a means to address that.
[01:18:08] So, whether you're working with internal groups or external groups - and by the way, we work with a number of external groups. We, Anonos, are a software vendor. But if you need access to groups who can help you understand part of the broader issues that we're talking about, happy to work with your existing groups, internal or external, or can refer you to those that we work with external. Our focus is on our subject matter expertise, which is the ability to deliver software that separates identity from information value, so you get the benefit of both.
[01:18:37] The next question I'd like to touch upon is Brexit. And I'd love to get Maggie's perspective on this as well. The reality is to me, Brexit is very telling and why I say that is because the trade arrangement between the EU and the UK, many people - I have to tell you. I saw a lot of discussions in social media. “Oh, thank God, we got adequacy. Oh, we don't have to worry about this.” The reality is the trade deal identified the legitimate needs of both jurisdictions, the United Kingdom and the EU. And it provided for a period of time, during which transfers will not be held to be international data transfers. But if you notice, the UK Data Protection Authority issued an announcement and a recommendation that UK companies facilitate and cooperate with their EU customers to put alternative transfer mechanisms in place. I personally believe there will not be an adequacy decision between the EU and the UK, and the reason I say that is because I believe the days of adequacy decisions, while they will still exist, are less important than the days of having to have defensible technologically enforced measures that can protect the rights of EU data subjects while achieving the business goals. And those same capabilities will serve you well with cross border transfers outside of the EU and trying to achieve your business goals and objectives. Maggie, do you have any particular perspective on Brexit?
Magali Feys
[01:20:15] Well, yes, just that the treaty now signs, actually, from a legal point of view, and I don't want to bore you too much with that, but there were quite some academics working on that that actually the documents or the sort of legal texts as it is, is not adequate indeed to actually state or govern the aspect of international data transfer and data protection. So, just thinking that that solves the problem and that we are out of the woods now, I think is actually quite dangerous. Because from a legal perspective in the hierarchy of legal norms, it’s definitely not the right document and I tend to believe that. And secondly, will there be an adequacy finding? I could not say that as such but we can all agree because it was also indicated that the UK also has the surveillance laws. So, actually, the same problem would occur there. And once again, I think with Schrems II, we know now that we have to have the standard contractual clauses or the binding corporate rules. And next to that, the supplementary measures. And as Gary pointed out and Romain Robert did it but I also tend to agree with that. What I said in the beginning, there is not so much new under the sun with Schrems II. It’s the fact that actually, the mere fact that Data Protection by Design by having the supplementary measures as a process as a procedure within your company should already be there is something that follows from the GDPR, and I think it’s very understandable and we all have been there. We have implemented GDPR and definitely within the big companies there is a lot of work and you focus of course on that data register and on all the legal requirements, and I think the translation was not always made to really work as a sort of process procedure. But if it would have been done that, which brings significant difference in the way not in what you could do as a business but sometimes in the way how you have to do your business. But if that would have been done from the start or more taken into consideration, I think Schrems II would not have been the hassle or the earthquake it now was.
Gary LaFever
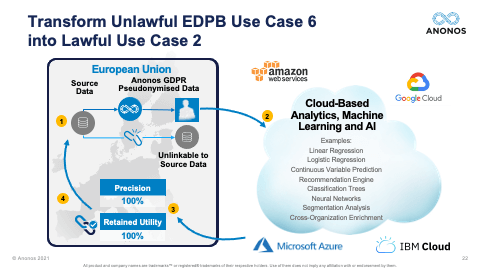
[01:23:02] So, time for one last question. It’s a very specific question. A registrant asks: “I use GCP - Google Cloud Platform. I send it to them. It's encrypted. They save it. It's encrypted. But when they process it, they decrypt it. How can I continue to avail myself of the many benefits of Google Cloud?” And I really want to emphasise that cloud is not about storage. Google Cloud, Azure, AWS - they have amazing capabilities, either that they offer themselves or through their partners through their cloud platform. And that is why people like to use the cloud because they get the benefit of those capabilities. So, this question is really identifying why it mentions GCP, you can fill in the blank, you know, and add IBM cloud to the mix. These are US-owned public clouds that provide real value and an EU data controller wants the benefit of that value. But at the time of processing, the data is in the clear, which means it's now unlawful.
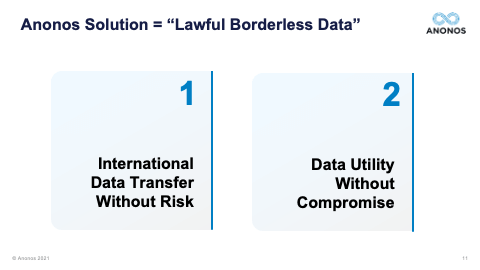
[01:24:05] How do I fix that situation? And again, what you can do is you can pseudonymise the data in the EU so what you’re submitting up to the cloud is pseudonymised and protected. We can show you. I will guarantee it. That's what the slide that's here. We guarantee that our software delivers 100% of the same accuracy as cleartext data for AI, analytics, machine learning, secondary processing, etc. And if it doesn't or a Data Protection Authority or a Court holds that our software does not comply, we give you the money back for our Quick Start Program. We really struggled to figure out how can we come up with something that says riskless as possible because this is a tough time and companies have to act. Six months have passed. What’s in your file to show the actions you've taken? What's your briefing been to the C-Suite and to the Board of Directors? And the bottomline is the answer to this person's question is if you pseudonymise the data and you send pseudonymised data to GCP, you will still get the same results back that you got before. And in fact, you may find that you have more opportunities. So, the reality is the opportunity to share and combine data lawfully to do cross border transfer, to use external capabilities like cloud processing, are actually enhanced and increased using Pseudonymisation.
[01:25:31] So, our time is up now. But I would like to encourage anyone that's interested to please contact me directly at gary.lafever (at) anonos.com and I'd be happy to do so. We have had several 100 people ask. We will schedule. And if you're really lucky, you'll get to talk to Maggie and not me. Seriously, though, it has been a pleasure for the two of us to speak with you and interact with you today. We hope this was worthwhile. You will all receive a copy of the Legal Solutions Guidebook, and we encourage you to reach out to us. This is something that must be addressed in a way that achieves the objectives of data use while honoring, respecting, and enforcing the fundamental rights of data subjects. Thank you very much. We hope you all have a good evening or day.
Magali Feys
[01:26:22] And one thing I think, Gary, you can say we saw a lot of Q&As coming in, so we also will see how we tackle them.
Gary LaFever
[01:26:29] Yes. Thank you very much, everybody. We appreciate the interaction. Thank you. Have a great day.
Magali Feys
[01:26:36] Thank you.